Thursday, March 31, 2005
Oei thesis available again
Matlab toolbox list available
GAs used in sequence analysis
The Hidden Markov Models (HMMs) are widely used for biological sequence analysis because of their ability to incorporate biological information in their structure. An automatic means of optimising the structure of HMMs would be highly desirable. To maintain biologically interpretable blocks inside the HMM, we used a Genetic Algorithm (GA) that has HMM blocks in its coding representation. We developed special genetics operations that maintain the useful HMM blocks. To prevent over-fitting a separate data set is used for comparing the performance of the HMMs to that used for the Baum-Welch training. The performance of this algorithm is applied to finding HMM structures for the promoter and coding region of C. jejuni. The GA-HMM was capable of finding a superior HMM to a hand-coded HMM designed for the same task which has been published in the literature.
Additional information is available here.
Company uses GAs in marketing applications
Wednesday, March 30, 2005
Graph my scenario
One tool that we have been extensively using for KeyGraph visualization is JUNG--an open source project..
JUNG--the Java Universal Network/Graph Framework--is a software library that provides a common and extendible language for the modeling, analysis, and visualization of data that can be represented as a graph or network. It is written in Java, which allows JUNG-based applications to make use of the extensive built-in capabilities of the Java API, as well as those of other existing third-party Java libraries.
You can learn more about JUNG or download it here.
Tuesday, March 29, 2005
Take an EC survey
GAs: The real gay science?
Sunday, March 27, 2005
Educating a penguin: Paying more for less
It was interesting being on the consumer end--as opposed to the professor end--of the university business, but it wasn't a pretty picture. All of the tours and admission sessions were impersonal, with crowds of 100 or more people in each session. Only Penn provided an adequate number of tour guides for the size of the group, marching out an impressive army of almost 20 tour guides. MIT tried to cover a group of a 100 or so people with a single student. Most of the tours went to 4 or 5 sites and filled up the time with material that repeated the repetitious info sessions (Penn was a notable exception with a thoughtful tour that covered the length and breadth of campus). The information sessions were uniformly tedious, providing essentially the same information as all the other info sessions (need blind admissions, need-based financial aid, faculty have office hours, most classes taught by faculty, etc.).
One interesting thing I learned was that the Ivies use a system of credit "units" or "half courses" in place of semester or quarter hours, and this system appears to mask a significant amount of degree duration deflation compared to degree duration at most public universities. For example, Harvard's system requires 32 half-courses for graduation. Math half courses meet three times a week for an hour over the course of a 13 week semester. English and history courses meet between two and three times a week for an hour. Doing the arithmetic, a Harvard undergrad in the liberal arts takes somewhere between 832 and 1248 contact hours of instruction over the course of his or her four years. Yale boasts that its students take 36 units to graduate, but Yale's academic calendar is somewhat shorter; moreover, a quick sampling reveals that many Yale course meet only two hours a week.
Comparing these figures to a public university such as the University of Illinois is instructive. A liberal arts major at the UIUC is required to take 120 credit hours, which roughly correspond to 120 contact hours, over the course of a 14.5-week semester. This totals 1740 contact hours. In other words, the Harvard grad, if my calculation is correct, is supposed to be in class only 48-72% of the total of the UIUC grad. Perhaps the Harvard student is so much better that he or she can learn 40 to 100 percent faster than the UIUC student to make up for the difference.
Harvard charges tuition and student fees totaling roughly $30k (the other Ivies are comparable), and lets assume that the average student has 1000 contact hours of coursework. The average Harvard student is paying $120 per contact hour of instruction. At that rate, a Harvard student could hire a personal tutor at an equivalent annual salary of nearly $250k/year.
Nonetheless, these elite institutions become more and more popular and selective each year, although if the duration deflation continues, it would be more appropriate to call them labeling clubs than schools. And which schools top Max's current list? Yale and Penn.
Wednesday, March 23, 2005
Visualizing the non-visual
Text-mining, where do I get started?
Monday, March 21, 2005
On the road with a penguin
Sunday, March 20, 2005
Lucille and the joy of text
Lucille Redmond in the Joy of text presents a nice and comprehensible look to the text mining challenges. Go and take a look at it, you may start realizing common needs share among text mining and the analysis of communications using chance discovery tools.
Friday, March 18, 2005
An economy of Powerpoint?
I usually find such arguments tedious. Lecturing goes on (and on and on) because it is an economical way for a single person to deliver a lot of stuff to a bunch of people. Active learning is only done in small measures in performance critical roles, because it is expensive (see this argument). In other words, active learning techniques are not used more often, because the marginal benefit of the activity (over lecturing ) does not usually exceed its marginal cost.
With this as background, I thought the Atkinson and Mayer's work was going to call for some complete overhaul of ppt and presentations. After all, we use Powerpoint because it is convenient and conveys a bunch of stuff fairly quickly; however, a closer read of the article gives a number of sensible suggestions for
- Clear headlines
- Digestible bites
- Offslide elaboration
- Visuals & words
- Removal of unneeded elements
In many cases, these steps can be taken without burdening the preparation or presentation process a bit. Elaborate visuals (number 4) can add marginally to the preparation time, but a well chosen schematic, block diagram, or picture can often benefit a presentation enough to make the added prep time worthwhile.
So I retract my first impression, but it is important to understand that Powerpoint is used as often as it is, because it is an economic alternative to other modes of presentation. Improving presentations is a laudable goal, but efficiency dictates that we balance the economy of Powerpoint in so doing.
Wednesday, March 16, 2005
7 ways to blog your way into a new job
- Start with a topic you're passionate about.
- Concentrate on shorter, more frequent entries in your blog
- Let your authentic voice emerge
- Use correct grammar and syntax (no misspellings allowed)
- Purposefully organize the content of your blog
- Post a new entry at least once a week, preferably two or three times a week
- Include your key contact information on your blog
- A bonus tip: Have fun when you blog.
Sounds like good advice for bloggers, in general. Are there circumstances when blogging might turn off a potential employer?
Tuesday, March 15, 2005
GAs part of BCS Grand Challenge
But quantum computing is not the only area of interest to non-classical computing researchers. Biological systems will provide it with much inspiration, says the BCS report, because living organisms have much to teach us about non-sequential, autonomous processing (consider, for example, how individual cells know what they should be doing without any central control).
Genetic algorithms and neurology will be an important part of this challenge, as will artificial immune systems. The Royal Mail has already trialed the latter as a means of automatically detecting fraud at its branches.
These systems require a new type of training and worker:
We are looking at new degrees where it is not just computer science-inspired biology or biology-inspired computing, it is a new type of person who understands how to build complex systems. To do that, they have to be both a computer scientist and a biologist
The grand challenge in this area is called in vivo-in silico (iViS), the creation of life on a computer.
Heuristics vs. algorithms: A harmful distinction
It's the human input that seems to contain all the "knowledge" an AI system has - something the designers and programmers already knew, and are trying to use the computer's speed and memory to use the concepts well. We're just not there yet with "self-learning" systems. Of course, there are randomness-based techniques to "learn" things (like genetic algorithms and genetic programming) that seem to fly in the face of all of this, but they're really just certain types of heuristics.
The author seeks a more human-like AI and suggests that GA and GP are qualitatively close in some sense, but then toward the end of the quotation we see how he is brought up short by the algorithm-heuristic categorization of his CS theory prof. Saying that GAs and GP are" really just certain types of heuristics" suggests that they are inferior to full fledged procedures accompanied by proof.
Elsewhere I have blogged on this topic. My main point was and is that in the realm of material machines (airplanes, toasters, automobiles), no such distinction is made, because proofs of convergence do not exist for the mass of things we use in our day to day lives. That is not to say that we don't understand the principles of operation of toasters, airplanes, automobiles and the like. We do, and we study the physics of different facets of their operation more closely as we need to improve their function (see here and here).
Let's bury the heuristic-algorithm distinction, or at the very least, let's acknowledge that the heuristic-algorithm axis is a continuum of mathematical understanding. Heuristics of differing stripes can function quite well, thank you very much, and many of them are backed with a good deal of mathematical understanding if not mathematical proof. Continuing to preface the term "heuristic" with the terms "merely," "just a," "only a," and the like is harmful, especially when it prevents us from grabbing the procedure we need to get the job done.
Sunday, March 13, 2005

A schematic of the DISCUS system shows an inner core innovation team surrounded by an interactive GA that evolves global stakeholder solutions for consideration.

Friday, March 11, 2005
Blaaarrgh! reading Pelikan's hBOA book
The latest on that queue is Hierarchical Bayesian Optimization Algorithm: Toward a New Generation of Evolutionary Algorithms. It is about what the title suggests, a scheme for utilizing a Bayesian Network for promising solutions, while sampling the built network for other solutions, which the network interjects back into the genetic algorithm.You should, too.
Thursday, March 10, 2005
Problems at O'Hare
Network effect kicks in for IB
Wednesday, March 09, 2005
DISCUS & the 4-quad chart
The DISCUS (distributed innovation and scalable collaboration in uncertain settings) project has been the subject of experimentation and a series of posts over the last few weeks, but IlliGAL Blogging has been somewhat remiss by not discussing the theoretical and computational underpinnings of that project more fully. The project dates to some work with Alex Kosorukoff (see Alex's Free Knowledge Exchange work that goes back to 1997) published at the 2002 GECCO conference (see paper here).
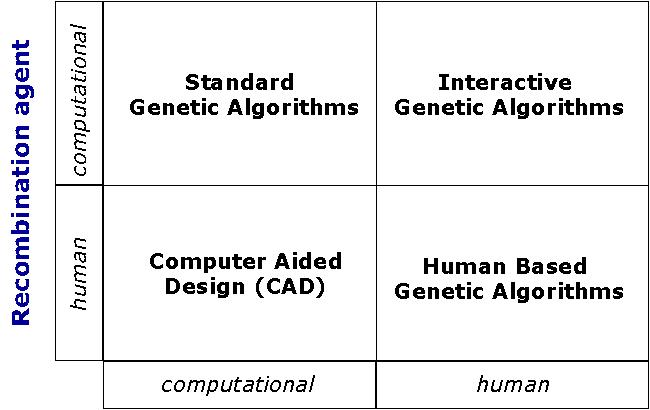
Who creates and who chooses. A 4-quad chart clarifies different types of GA.
The universe of concern is reasonably fairly but simple captured in the diagram above. The y-axis considers whether a human or computer is the innovating (recombinative in the diagram) agent, and the x-axis considers whether a human or computer is the choosing (selection) agent
This decomposition of the problem yields 4 quadrants worthy of our attention. For example, C-C (computer as innovator and chooser) is a regular run-of-the-mill GA with computational fitness function and genetic operators. The H-C quadrant (human chooser, computerized innovator) is an interactive GA. DISCUS is a hybrid of all four quads arranged systematically to organize the thoughts of a core innovation team (of humans), computational agents, and human stakeholders affected by and affecting a design effort. More DISCUS publications and presentations are available here.
GECCO snags Endy as keynoter
Biology is going through a fundamental transition – from preexisting, natural, and evolving systems, to synthetic, engineered, and disposable systems. Here, I will discuss (i) our ‘refactoring’ of a natural biological system, bacteriophage T7, (ii) the adaptation and application of three past lessons – standardization, abstraction, and decoupling – that seem relevant to the engineering of biology today, (iii) how solving the problems of error detection and correction in reproducing machines might lead to interesting compromises in system architecture, and (iv) some of the social, political, and risk opportunities and pitfalls worth considering as we begin to systematically engineer the living world.More keynote info is available here.
Why do academics blog?
- If you’re an academic who blogs, what prompted you to start blogging?
- And what keeps you going? What do you try to do in your blog?
- Does your blog have any relationship to your scholarship?
- If you’re an academic who just reads blogs, do you intend to start your own blog sometime?
- If yes, what are the reasons that you haven’t done so at this point in time?
- If no, why not? Either way, what do you get from reading blogs?
The responses are diverse, interesting, and well worth reading. One comment said that academic blogging could be viewed as "pre-scholarship," that blogging can be a research organizer and filing system as well as inspiration for future talks and writing. Another comment resonated strongly with my recent experiences with blogging, discourse, and social networking:
Academic blogs make me feel like I’m not alone in this enterprise.
Being an academic can be isolating. Working in a room, on some obscure topic, with mainly graduate students to talk to, blogging offers a way to have an interchange of ideas with a self-selecting group of people who find your writing interesting, challenging, or simply maddening. With its emergent topology of interconnection, serendipitous collection of correspondents, and adaptive fitness function of attention, blogging helps return academic process to its discursive ideal.
None of this addresses our earlier attention to the dearth of bloggers among academic leaders, but it is clear that, at the very least, a good and growing group of academics in the trenches are making peace with blogging, even finding solace in it.
Is blogging journalism?
And for the spanish-speaking bloggers, the second mini-conference on media & blogging (approximate title translation) will be held next week in Granada, Spain, organized by an EC researcher, J.J. Merelo
Tuesday, March 08, 2005
DISCUS & a 3-way pickle blogging echo
Darwinia: GA as cultural artifact
Darwinia opens with an amazing sequence that immersed me right into the feel of the game. Dr Sepulveda welcomes you to Darwinia and explains that a nasty virus has infected this virtual world and is killing his life's work, the Darwinians. The supposed result of genetic algorithms.
It is your job to create units, and retake Darwinia one area at a time (tis a ye-olde-strategy game). The graphics are nice, the sounds are original (inspired by 80's gaming soundtracks) and the interface is workable. I say workable because to create units you must use a simple mouse gesture system.
Many, if not most, of the Japanese card games/cartoons that are now popular in boydom around the planet, from Pikachu to Yu-Gi-Oh, draw inspiration from artificial evolution, and this is not surprising given that genetic algorithms were a fairly popular subject on TV and in the newspapers Japan during the 1990s. Michael Crichton's bestseller Prey is another example of GA-as-cultural-artifact.
What other example can readers of this blog come up with? Why not take a moment and post a comment on your favorite GA cultural artifact?
The "modeling" spectrum
David Goldberg on blogging in Corporate vs. academic blogging; and also about the utility of models in Models live in the error-cost plane. In the latter case, I think there’s more to the word “model” than he’s caught yet, but that he’s on the right track….I'll return to corporate vs. academic blogging later, but I hope my notion of a model is big enough to capture what the Slurrier has in mind. Let me draw a picture:
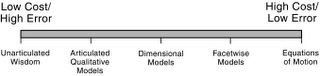
The modeling spectrum goes from unarticulated knowledge to equations of motion.
On the right we have the usual sort of post-Baconian model, an equation of motion such as Newton's second law or a Markov chain, something with some red mathematical meat on it. What we 21st century modeling brats take for granted as a "model." On the left, we have a thought, a feeling, an intuition, a knowing that we have some trouble talking about. Polanyi called this sort of thing tacit knowledge, and Sowell called it unarticulated knowledge, and the error-cost plane applies to the whole lot.
I'm particularly interested in the modeling middle, especially the transition point when we move from articulated qualitative models (verbal or graphical representations) and we cross over to those models that are barely quantitative (simple measurements and dimensional reasoning), and I'll talk more about those in other posts, but I wanted to clarify that the project of The Design of Innovation is deceptively larger than might be inferred from the term "model."
Evolver used in portfolio management
Monday, March 07, 2005
The academy vs. blogging?
Mr Tozier links to a Left2Right post describing emergent intelligence in the human academic ecosystem. (See also Susanne Lohmann's forthcoming book on the American university, How Universities Think, ) Really, blogs only stand to make that ecosystem more efficient with wider, faster distribution, wherein readers more easily find better niche content.
Oooh, that's an interesting thought, and Anderson continues by suggesting that academics not only will not embrace the blogosphere, they will fight it, because it challenges their presumed intellectual authority. Put another way, the suggestion is that academics might fight the blogosphere in the same way and for some of the same reasons the mainstream media has. Silly academic ideas and silly research can not stand the scrutiny of open source fact checking and smell testing any more than Dan Rather or Trent Lott could.
This is an interesting line of reasoning, and I agree that some academics will eschew pajamahadeen (pajamahadean, perhaps?) status for fear of unwanted attention; however, just as some MSM journalists started blogs and otherwise paid attention to the blogosphere, some academicians will embrace the blogosphere and face the relentless scrutiny of an open source world. They, their research, and and the state of knowledge will probably be better off for it.
Red wine and genetic algorithms
I was tooling around the blogosphere with Technorati and I came across a list of papers on Dr. Susanna Buratti's blog. One particular paper was near and dear to my heart (palette??):
S. Buratti, D. Ballabio, S. Benedetti, M.S. Cosio. Prediction of Italian red wine sensorial descriptors from electronic nose, electronic tongue and spectrophotometric measurements by means of Genetic Algorithms regression models. In pubblicazione su Food Chemistry (2005), Submitted.
Simply put, Dr. Buratti has been using advanced sensor technology and genetic algorithms to make better red wines. Now, who can say that genetic algorithms have not led to anything useful?
GAs, baseball & the Hall of Fame
Apparently the rule is as follows:
if
Games >2794 and AB >3967 and Runs >1145 and Hits >1297 and TotalBases >4432 and Doubles >252 and Triples >14 and HR >355 and RBI >325 and StolenBases >341 and BB >658 and HBP >9 and Strikeouts <2087>9 and Psbb >1 and Psstrikeouts <42>0.269 and PSOBP >0.010
then
its Cooperstown Time
Read the whole paper here. Now, if only someone would use a GA to determine what it takes to get tenure at a major research university.
Models live in the error-cost plane
In The Design of Innovation, I spend a fair amount of time talking about the economy of modeling, arguing that models live in an error-cost plane:
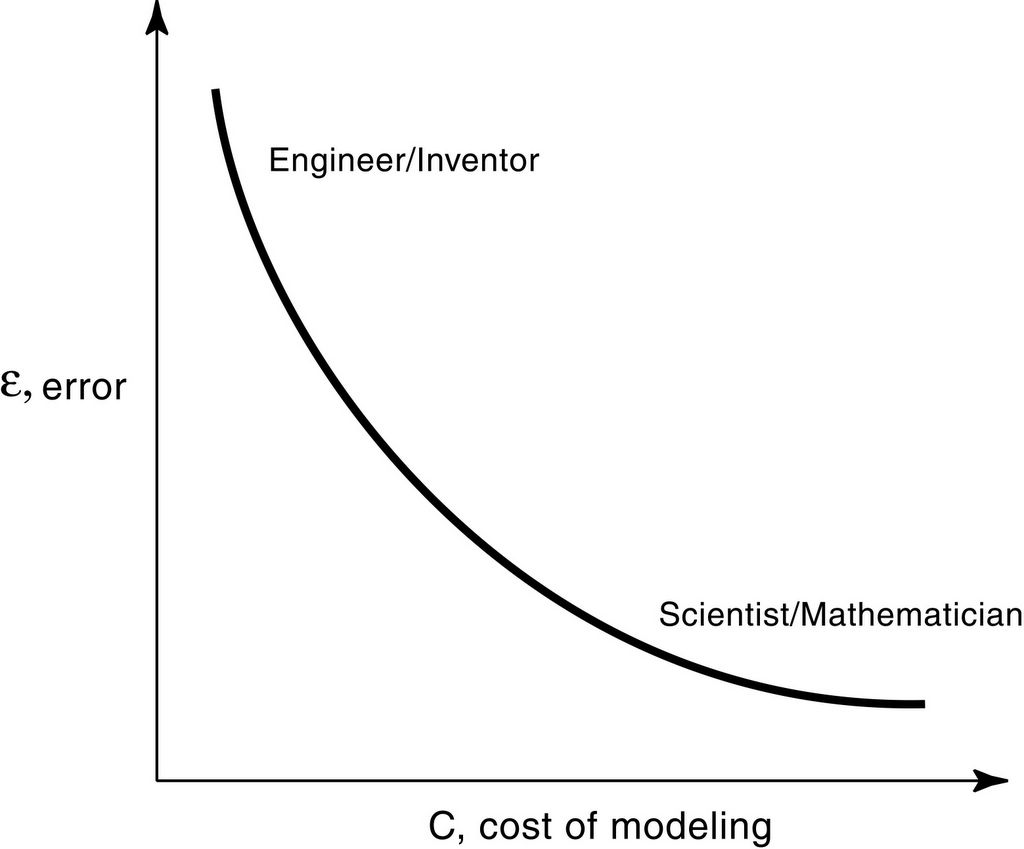
When scientists or mathematicians build models, they are largely interested in developing more accurate models of the world whatever the costs of so doing. When engineers or inventors use models, they are generally interested in designing better gizmos. As a result, an implicit cost-benefit calculation comes into play.
Specifically engineers tend to weigh the marginal costs of modeling against the the marginal benefits of the modeling to the technology being developed. As a result, engineers generally build and use models that are less sophisticated than the most sophisticated models available, but that choice is guided, not by simple-mindedness, but by a desire to be efficient in the race to build better technology.
Economical thinking or modeling in this way has been extraordinarily helpful in moving quickly to build little models that maximally advance the state of genetic algorithm art. The approach may not be as elegant as some, but it does give a terrific amount of insight for the amount of effort expended (see my 1 Feb post here on a similar subject).
Sunday, March 06, 2005
DISCUS series make blog & focus-group history
The series is noteworthy from a blogging perspective, because it represents the first time IlliGAL Blogging has covered ongoing lab research in real time.
The experiments were noteworthy, because they helped demonstrate the effectiveness of DISCUS technology in augmenting marketing focus groups. As we analyze the data, tech reports and papers will be written and published, but we already know that the results were important enough to keep working toward testing in the marketplace.
Publications and presentations on DISCUS are available here.
Saturday, March 05, 2005
King comments on academic blogging
This has the ring of truth. Many academics are extraordinarily conservative, and working on an edgy topic such as genetic algorithms for the better part of 25 years has been liberating, and a load of fun. But occasionally I forget the rules of the academic game. Thanks, Steve, for reminding me what planet I'm on, and for the sake of my reputation, I should probably shut IlliGAL Blogging down. Naaaaaahhhhh!! Keep on bloggin' momma, bloggin' your blues away.I think the main reason we aren't seeing more academic blogs is cultural. In academic settings people are rewarded for deep and thorough analysis, and academic writings tend to be scrutinized by their peers. Because of this, academics tend to be very careful about what they "publish".
Writing compelling blog posts
Additionally, the article has useful hints about layout, editing, and writing blog comments. Go read the whole thing. It's well worth the short time it takes to register.Adopt a direct style. Declarative sentences are good. Web readers demand them.
Link like crazy. One thing that distinguishes blog posts from dead-tree journalism is that bloggers link prodigiously. Link to any other blog or Web site you mention. Link to articles, books, products, bios, explanatory materials on other sites and anything you mention in your blog. Always link to information that clarifies or gives background on information and opinions in your post.
Write less. Omit all unnecessary words. The best advice I ever got about writing was from my first boss, the late "press agent" Leo Miller, who taught me a game to play with sentences. He'd keep taking out words until removing one more word destroyed the meaning of the sentence. For example: He'd take out words until removing another destroyed the sentence meaning. Aim at keeping your posts at about 250 words.Write good headlines. Most people use a news feeders like News Gator to scan blog headlines. They decide after seeing the headline to click into the post. Tell as much of the story as you can in the headline.
Corporate vs. academic blogging
MANE IT Network has a post on academic blogging that links to a nice article (registration required) in the Guardian that lays out the landscape of academic blogging. At this point, it appears largely to be a grassroots affair by faculty and students. The Guardian article cites a number of uses of academic blog, none of them administrative:
- Blogging to organize research
- Blogging as knowledge management
- Blogging as social networking
- Blogging as dissemination tool
- Blogging as teaching tool
- Blogging as device to increase research accountability
Many of the emerging rules and guidelines established for corporate bloggers, are appropriate for blogging within and about academic institutions. An April 2004 MarketingProfs article lists and elaborates on 10 Rules for Corporate Blogs and Wikis here (signup required):
- Be authentic
- Be an unmatched resource
- Once you start, don’t stop
- Keep it relevant
- Measure your effectiveness
- Monitor other blogs
- Trust your employees
- Use blogs for knowledge management
- Use wikis for employee and customer collaboration
- Develop an organizational content strategy now
Sounds good to me. Now let's see if all you profs, deans, department heads, and university presidents can keep up with Bob Lutz.
Largest, diverse tutorial slate at GECCO
Intro
Genetic Algorithms: Erik Goodman
Genetic Programming: John Koza
Evolution Strategies: Thomas Baeck
A Unified Approach to EC: Ken DeJong
Evolvable Hardware I: Tetsuya Higuchi
Linear GP: Wolfgang Banzhaf
Ant Colony Optimization: Christian Blum
Particle Swarm Intelligence: Russell Eberhart
Learning Classifier Systems: Tim Kovacs
Advanced
No Free Lunch (NFL), Darrell Whitley
Genetic Algorithm Theory, Jonathan Rowe
Bioinformatics, James A. Foster
Taxonomy and Coarse Graining in EC, Chris Stephens
Multiobjective Optimization with EC, Eckart Zitzler
Computational Complexity and EC, Ingo Wegener
Evolvable Hardware II, Adrian Stoica
Representations, Franz Rothlauf
Building on Biological Evolution, Ingo Rechenberg
Principled Efficiency Enhancement, Kumara Sastry
Generalized Hill Climbing Algorithms, Sheldon H. Jacobson
Statistics for EC, Steffan Christensen, Mark Wineberg
Applications & Techniques
Symbolic Regression in Genetic Programming, Maarten Keijzer
Grammatical Evolution, Conor Ryan
Quantum Computing, Lee Spector
Evolutionary Robotics, Dario Floreano
Evolutionary Music, Al Biles
Evolution and Resiliency, Terry Soule
Evolutionary Design, Ian Parmee
Interactive Evolution, Hideyuki Takagi
Optimization of Dynamic Environments, Juergen Branke
Spatially Structured EAs, Marco Tomassini
How to Start a GA Company, Zbigniew Michalewicz
Industrial Evolutionary Computation, A. Kordon, G. Smits, M. Kotanchek
In Vitro Molecular Evolution, Byoung-Tak Zhang
Evolving Neural Networks, Risto Mikkulainen
Experimental Research in EC, Mike Preuss, Thomas Bartz-Beielstein
Fitness Approximation in EC, Yaochu Jin, Khaled Rasheed
Constraint-handling Techniques used with EAs, Carlos Coello-Coello
The XCS Learning Classifier System: From Theory to Application, Martin Butz
Experiences Implementing a GA-Based Optimizer in an Aerospace Engineering Application, Thomas Dickens
Fitness Landscapes and Problem Difficulty, Jean-Paul Watson
A number of the tutorials are being given by IlliGAL Blogging bloggers (Butz, Rothlauf, Sastry, and Takagi). Many conferences charge hundreds of dollars more for tutorial registration, but GECCO tutorials (and workshops) are included in the price of admission. If you're new to the genetic algorithms game or if you're an old hand wanting to brush up on the latest tricks, techniques, and applications, GECCO has tutorials to get you up to speed. More information is available on the tutorial page here.
Friday, March 04, 2005
Clean the table my friend!
The six DISCUS sessions covered a total of eight different focus groups in three days. In a conventional setting without DISCUS assistance, it takes---quoting Yuichi’s words---three days to complete one focus group. Stepping in the Union the reasons of their excitement became crystal clear to me :)
We wrapped an exciting week sitting at the Expresso Royale Café of Urbana. Sitting around coffees and chais we reviewed the main results of the experiment. But looking into the past was not all we did. We started already exploring the new exiting possibilities of improvement and innovation for DISCUS. Today is not an end. Today is the beginning of a whole new reborn DISCUS. A DISCUS that has celebrated its second anniversary proving that the vision could become a reality, opening the door to new and even more exciting things to come.
However, there was only one thing left to do today. Get all together and celebrate that we made it! What could be better than to have a nice Thai dinner and to relax playing pool. So, let’s clean the table my friend, let’s clean the table all together.

The milestone of the day: We wrapped up. Our colleagues have already in their hands all the data and paper work done. We wish them a pleasant flight back. I guess I have already said this several times these days, but this was no one-man job. Chen-Ju, Abhimanyu, Mohit, and Davina you did a great job. I am proud of you and your work. Nothing would have been the same without you unconditional effort to get this strait. By the way, Yukio, Davina, we missed you tonight.

Thursday, March 03, 2005
Last lap, tomorrow

Now that we have only one more session to go tomorrow morning, we need to admit that we are happy with the new input and possibilities unveiling in front of us. This experiment is becoming a main milestone for DISCUS. Besides the usefulness of the discussions of the participants for our colleagues in marketing research, we are also collecting valuable feedback about the usability, interpretability, and potential new ways to support innovation and creativity.


The milestone of the day: We tested a new approach to the creation of focus groups. DISCUS was able to support large heterogeneous groups with no special arrangements.
Fav picks on E&R blog
GAs, DNA & bioinformatics
Biological applications of genetic algorithms are deliciously circular (procedures inspired by nature used to understand natural procedures), and the BioGEC workshop at GECCO is a good place to meet key players and learn about recent work.GANN is a machine learning method designed with the complexities of transcriptional regulation in mind. The key principle is that regulatory regions are composed of features such as consensus strings, characterized binding sites, and DNA structural properties. GANN identifies these features in a set of sequences, and then identifies combinations of features that can differentiate between the positive set (sequences with known or putative regulatory function) and the negative set (sequences with no regulatory function). Once these features have been identified, they can be used to classify new sequences of unknown function.
- Artificial Neural Networks are used for pattern detection, because they can model complex interactions between input variables (i.e., the features). This can be potentially very important if the positive set contains different types of regulatory regions that must all be classified.
- The number of sequence encodings that can be generated is practically infinite, and even a reasonable number (a few hundred) are too much to present to the neural network at once. The Outer Genetic Algorithm (OGA) was designed to test different subsets from the pool of available representations, and generate new subsets using evolutionary operations.
Wednesday, March 02, 2005
Solid rocket booster


Today we had a first hand validating result using common users (mostly UIUC students) in a real-world scenario (marketing scenarios for cell phones). The previous photos show one of the biggest experiments conducted this week using DISCUS. Fourteen students used only DISCUS to communicate among them in the focus groups for cell phone usage focus groups. In less than 30 minutes, more than 100 messages were posted and analyze. Right now, we are collecting a large volume of information about how the users interacted among them using DISCUS. We are really thrilled about the possibilities that DISCUS and this week of experiment are opening.
The milestone of the day: Chance Discovery Consortium and DISCUS researchers analyzing and creating new cell phone scenarios in the largest session held till now using DISCUS. Yes, the picture below does not lie; Nao is back in town for a few days :)

GE alum wins Oscar
GAs in search personalization?
Future? "personalization. It’s misunderstood, personalization. It’s not giving you a search just for you. Its about returning results for your peer group. They can start to tailor the search specifically to you. There is data now using genetic algorithms and others set that are using these to create search engines. Mike concludes the more information we give the search engines, the better our experience will be."Yes, but how and where?
Tuesday, March 01, 2005
Rock & Roll

The photo shown above was taken while participants were instructed on how to proceed during the experiment. Researchers and participants gathered together to minimize uncontrolled elements during the experiment. For instance, participants were told not to communicate to each other using any other channel than the computer-mediated DISCUS. Tomorrow we are going to have two rounds of experiments involving 20 participants in total (instead of the 5 involved today).
The milestone of the day: Abhimanyu Gupta and Mohit Jolly---below---polishing DISCUS to get it bright and shiny, and most important, purring like a kitty.

Seeing chemical Daylight and GAs
The Daylight Toolkit enables companies to build applications to add a broad range of cheminformatics capabilities to their environment. These tools empower our customers to easily assemble customized systems which give them total control over corporate chemistry.
Although the basic Toolkit does not apparently contain genetic algorithms, a search of the web site reveals a number of user group papers using GAs (type "genetic algorithms" into the search box). An article on www.nature.com (subscription required) discusses use of Daylight and GAs to infer molecule structure from empirical data.
![]()

